728x90
반응형
아파치 스파크(Apache Spark) 란?
- 고속 범용 분산 컴퓨팅 플랫폼.
- 홈페이지
- 스파크의 설계자
- UC 버클리 AMPLab
- 마테이 자하리아
- 이온 스토이카
- 그리고 레이놀드 신
- 패트릭 웬델
- 앤디 콘윈스키
- 알리 고시
- 추후, 데이터브릭스(Databricks)를 창업함.
- https://databricks.com/

- 그리고, 데이터브릭스 클라우드(Databricks Cloud) 라는 스파크 기반의 빅데이터 분석 솔루션을 사용화함.
- UC 버클리 AMPLab
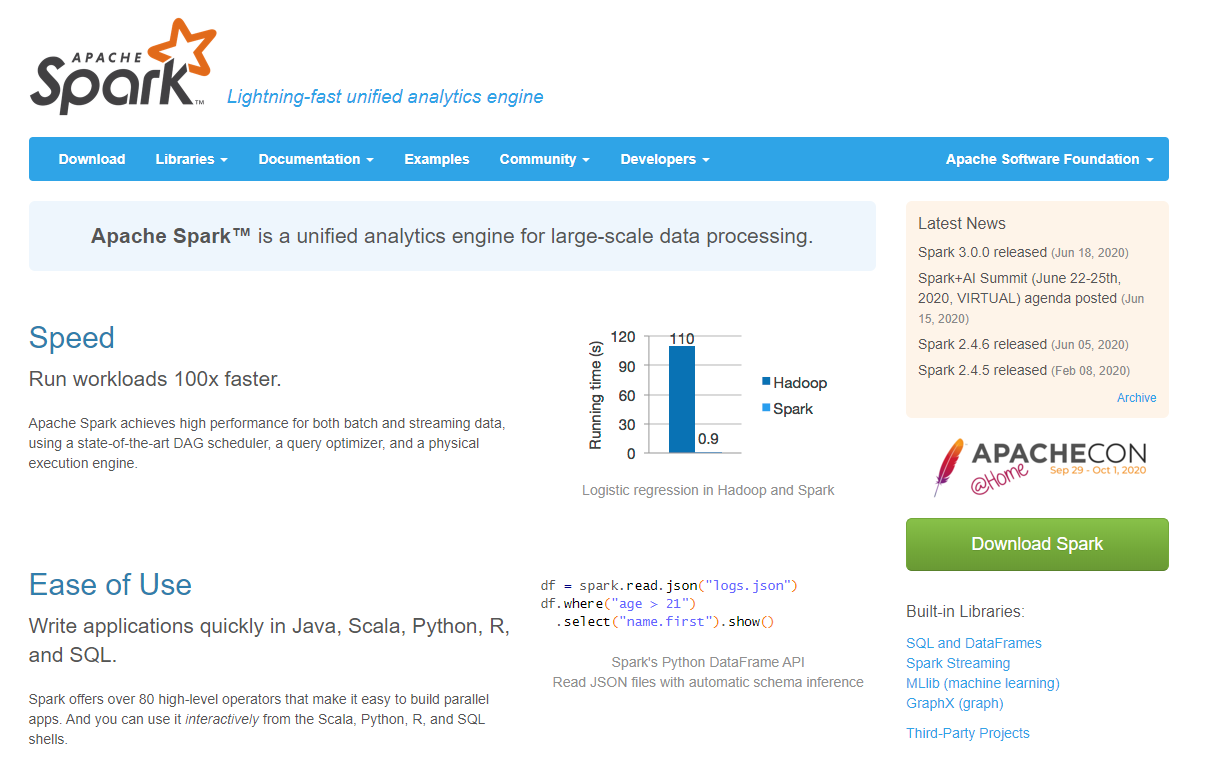
그럼, 아파치 스파크의 특징에 대해서 알아보자.
- 하둡 맵리듀스(Hadoop MapReduce)를 대체하는 흥미롭고 새로운 빅데이터 처리 지원
- 잠깐!) 아파치 하둡(Apache Hadoop) 에 대해서 잠시 알아보자.
- 홈페이지
- https://hadoop.apache.org/
- 하둡은 분산 컴퓨팅용 자바 기반 오픈소스 프레임워크
- 구성은 아래와 같음.
- 하둡 분산 파일 시스템(Hadoop Dstributed File System, HDFS)
- 맵리듀스 처리 엔진
- 스파크의 유사성은
- 범용 분산 컴퓨팅 플랫폼이라는 점.
- but, 스파크는 메모리를 효율적으로 활용하여, 하둡 맵리듀스보다 10~100 배 더 빠른 속도를 가짐.
- 사용자가 클러스터를 다루고 있다는 사실을 인지할 필요가 없도록, 설계된 컬렉션 기반의 API 를 제공함.
- 그럼, 스파크의 강점은 ?
- 스파크 컬렉션은 여러 노드에 분산된 데이터를 참조함.
- 즉, 사용자가 스파크 컬렉션에 적용한 연산은 복잡한 병렬 프로그램으로 자동 변환됨.
- 해당 과정을 사용자가 굳이 알 필요가 없다는 것이 강점임.
- 스파크에서는 데이터 처리작업에 적합한 함수형 프로그래밍 방식을 사용할 수 있음.
그럼, 아파치 스파크의 주요 기능에 대해서 알아보자.
- 일괄처리기능
- 실시간 데이터 처리 기능
- SQL과 유사한 정형 데이터 처리기능
- 그래프 알고리즘
- 머신러닝 알고리즘
- 기타 등등,
- 모두를 단일 프레임워크와 통합함.
- 즉, 빅데이터 어플리케이션에 필요한 대부분의 요구사항을 만족시킬 수 있음을 의미함.
그럼, 스파크의 단점은 무엇일까?
- 하나, 분산 아키텍처 때문에 처리 시간에 약간의 오버헤드가 필연적으로 발생함.
- 대량의 데이터를 다룰 때는 오버헤드가 무시할 수준
- but, 단일 머신에서도 충분히 처리할 수 있는 데이터 셋을 다룰 때는 작은 데이터셋에 최적화된 다른 프레임워크를 사용하는게 더 효율적이라고 함.
- 둘, 온라인트랜잭션처리(OLTP, OnLine Transaction Processing) 어플리케이션을 염두에 두고 설계되지 않음.
- 다시말해서, 대량의 원자성 트랜잭션을 빠르게 처리해야 하는 작업에는 스파크가 적합하지 않음.
- but, 일괄 처리 작업 or 데이터 마이닝같은 온라인분석처리(OLAP, OnLine Analytical Processing) 작업에 최적화 되어 있음.
그럼, 스파크가 지원하는 언어에 대해서 알아보자.
- 파이썬
- 자바
- 스칼라
- R
- 기타 등등.
마지막으로, 스파크의 핵심을 알아보자.
- 맵리듀스처럼 잡에 필요한 데이터를 디스크에서 매번 가져오는 대신, 데이터를 메모리에 캐시로 저장하는 인-메모리 실행 모델이다라는 점은 꼭 머리에 넣어두자 ^^! (즉, 빠르다 라는 것!)
- 보통 스파크는 동일한 작업을 맵리듀스보다 최대 100배 더 빠르게 실행할 수 있다고 함.
- 참고페이지
- https://amplab.cs.berkeley.edu/wp-content/uploads/2013/02/shark_sigmod2013.pdf
- 여기서 잠깐!) shark 는 무엇일까?
- Shark is an open source Hadoop project that uses the Apache Spark advanced execution engine to accelerate SQL-like queries.
- 즉, Shark는 Apache Spark 고급 실행 엔진을 사용하여 SQL과 유사한 쿼리를 가속화하는 오픈 소스 Hadoop 프로젝트임.
- 스파크의 성능을 입증했던 적도 있었다.
- 2014년 10월에 열린 데이토나 그레이 정렬 대회에서 스파크는 100TB 를 1406초 만에 정렬하는 세계신기록을 세움
- 참고페이지

결론
- 아파치 스파크(Apache Spark)는 고속 범용 분산 컴퓨팅 플랫폼임.
- 아파치 스파크는 하둡 맵리듀스(Hadoop MapReduce)를 대체하는 흥미롭고 새로운 빅데이터 처리 지원함.
- 빅데이터 어플리케이션에 필요한 대부분의 요구사항을 만족시킴.
- 스파크의 단점은
- 하나, 분산 아키텍처 때문에 처리 시간에 약간의 오버헤드가 필연적으로 발생함.
- 둘, 온라인트랜잭션처리(OLTP, OnLine Transaction Processing) 어플리케이션을 염두에 두고 설계되지 않음.
- 스파크의 핵심은 맵리듀스처럼 잡에 필요한 데이터를 디스크에서 매번 가져오는 대신, 데이터를 메모리에 캐시로 저장하는 인-메모리 실행 모델이다라는 점
- 꼭! 머리에 넣어두자 ^^
- 오늘도 아파치 스파크에 대해서 개념하나 머리속에 저장 완료! 감사합니다. ^^
- 오늘의 명언 한마디
- 자신을 타인과 비교하지 않고 있는 그대로 바라볼 때, 우리는 내안에 숨겨진 재능을 발견하게 되고, 그 순간부터 진정한 변화는 시작된다.
- 대열속에 합류하면서 안도하지 말고, "나만의 영역과주제"를 찾아 나서자.
- 자신의 능력과 적성에 따라 "가장 자기답게 살 수 있는 방법"에 대해서 고민해보자.
- 그리고, 나만의 전문성을 발전시키면서 세상에 유일한 "온리원 브랜드"로 거듭나길 바란다.
- 이지영지음, "엄마의 첫 부동산 공부" 중에서...
- 오늘의 영어 한마디
- This is form must be handed in with you proposal.
- 이 서식은 / 제출되어야 한다. / 제안서와 함께
- 설명
- "form" 은 서식을 의미함.
- "hand in~" 은 "~을 제출하다" 라는 의미.
- This is form must be handed in with you proposal.
- 오늘의 민법 한마디
- 제1편 총칙 / 제7장 소멸시효
-
제162조(채권, 재산권의 소멸시효)
-
1. 채권은 10년간 행사하지 아니하면 소멸시효가 완성한다.
-
2. 채권 및 소유권 이외의 재산권은 20년간 행사하지 아니하면 소멸시효가 완성한다.
-
-
- 제1편 총칙 / 제7장 소멸시효
- 오늘의 재무제표 공부 한마디
- 선입선출법
- 재고자산의 원가 계산방법 중 하나.
- 재고자산이 출고될 때 장부상 먼저 입고된 것으로 되어있는 상품부터 출고된 것으로 간주하는 방법
- 한마디로 먼저 들어온 물건이 먼저 팔린 것으로 치는 방법
- 실제로는 어떤 순서로 출고되건 상관없다. 다만 장부상의 기록일 뿐.
- 선입선출법
- 나의 목표 및 다짐을 항상 내곁에 두기.
- 목표
- 나의 강점을 바탕으로 나의 일을 잘해냄으로써 타인과 사회를 아릅답게 만든다.
- 현재 내가 가진 능력으로 누군가에 도움이 될 수 있을까? 에 대해서 항상 생각하기
- 목표를 이루기 위한 실천방안
- 꾸준한 블로깅/기록법/독서법으로 넘버원이 아닌 온리원이 되보자.
- 천사불여일행(千思不如一行)을 항상생각하며 체화 및 각인시키자.
- "천번 생각하는것보다 한번 행동하는 것이 더 중요하다."
- 기기일약 불능십보(騏驥一躍 不能十步) / 노마십가 공재불사(駑馬十駕 功在不舍)
- 천리마도 한번에 열걸음을 뛸 수 없고, 느리고 둔한말이라도 열흘이면 하룻길을 간다.
- 목표
728x90
300x250