
블로그 목적 :
Selenium Library를 이용한 검색사이트 결과를 자동으로 수집하기에 대해서 공부및 정리후 나만의 노하우와 지식을 공유한다.
블로그 요약
selenium 프로젝트에 대해서 알아본다.
selenium 라이브러리를 이용해서, 특정 검색사이트에서 특정 내용을 추출해본다.
블로그 상세 내용
우선, selenium 프로젝트를 알아볼까요?
Selenium은 웹 브라우저의 자동화를 지원하고 지원하는 다양한 도구 및 라이브러리를 위한 포괄적인 프로젝트를 말하는데요..
브라우저와의 사용자 상호 작용을 에뮬레이트하는 확장, 브라우저 할당 확장을 위한 배포 서버, 모든 주요 웹 브라우저에 대해 상호 교환 가능한 코드를 작성할 수 있는 W3C WebDriver 사양 구현을 위한 인프라를 제공한다고 하네요..

알아보니...아래와 같이, Java, Python, C#, Ruby, Javascript, Kotilin 언어를 지원하고 있었습니다.

그리고, 공부해보니 아래와 같이 크게 3가지 프로젝트 구성요소가 있었는데요..
- 아래와 같이 webdriver / ide / grid 가 있네요..
하나, WebDriver 는 브라우저 공급업체에서 제공하는 브라우저 자동화 API를 사용하여 브라우저를 제어하고 테스트를 실행한다고 하고요. 이것은 실제 사용자가 브라우저를 조작하는 것과 같다고 하네요...
- 참고로 이번 블로그에서는 해당 기능을 사용할 예정입니다.
둘, IDE (통합 개발 환경)는 Selenium 테스트 케이스를 개발하는 데 사용하는 도구라고 하고요.
- 사용하기 쉬운 Chrome 및 Firefox 확장 프로그램이며 일반적으로 테스트 사례를 개발하는 가장 효율적인 방법이라고 하네요.
셋, Selenium Grid를 사용하면 다양한 플랫폼의 다양한 시스템에서 테스트 케이스를 실행할 수 있다고 하고요.
- 테스트 케이스를 트리거하는 제어는 로컬 측에서 이루어지며 테스트 케이스가 트리거되면 원격 측에서 자동으로 실행된다고 하네요..

아무튼, 해당 내용들도 조금씩 시간날때마다 공부해볼 계획입니다.
그럼, selenium 라이브러리를 이용해서, 특정 검색사이트에서 특정 내용을 추출해보려고합니다.
우선, selenium 을 통해서 자동으로 브라우저를 띄워, 우리나라 1위 검색사이트 네이버로 이동하는 것을 시작으로, 해당 사이트에서 특정 내용을 추출해 보겠습니다.
- 프로그래밍 목적 : devocean 으로 네이버에 검색했을때, 해당 devocean 를 다루는 상위 View를 추출해본다.
우선, 위의 요구사항을 처리하기 위해서는 "웹사이트" 분석을 위해서 배경지식이 필요한데요...
- 보통 HTML 의 "태그"라고 불리는 요소 입니다.
웹사이트는 HTML의 "태그" 라고 하는 여러요소로 구성되어 있습니다. (HTML에 대해서 모두 아시고 계신다는 가정을 하고 해당 내용 설명은 기초적인 지식이라 생략을 하겠습니다. )
두번째로, 자동으로 브라우저를 띄우고, 네이버 페이지로 이동하려면, 위에서 잠시 알아본 selenium 라이브러리를 이용하면 되는데요..
설치는 아래 명령을 통해서 진행하시면 됩니다.
$ python -m pip install selenium정상적으로 설치 되었는지 확인은 아래와 같이 진행하시면 되고요..

정상적으로 버전이 출력되는 것을 확인한바, 잘 설치가 되었네요..
세번째로, 크롬 드라이버 설치가 필요합니다.
selenium 라이브러리는 웹 브라우저를 직접 실행시켜 자동화를 수행하는데요.
이 부분이 실행되려면, 해당 내용을 지원하기 위한 브라우저 드라이버가 있어야 합니다.
우리는 "크롬드라이버" 를 사용해서 자동화를 진행하겠습니다.
"크롬드라이버" 는 아래 사이트에서 다운로드 받을 수 있습니다.
https://chromedriver.chromium.org/downloads
ChromeDriver - WebDriver for Chrome - Downloads
Current Releases If you are using Chrome version 100, please download ChromeDriver 100.0.4896.20 If you are using Chrome version 99, please download ChromeDriver 99.0.4844.51 If you are using Chrome version 98, please download ChromeDriver 98.0.4758.102 Fo
chromedriver.chromium.org

크롬드라이버를 다운로드 받기전에 현재 본인이 사용하고 있는 크롬 정보를 알아야됩니다. 왜냐하면 호환이 가능해야 정상적으로 작동을 하기때문입니다. (도움말 > Chrome 정보)

확인하셨으면, 크롬 버전과 운영체제에 맞는 드라이버를 다운로드 받으시면되고요..
자동화 작업을 위해서, 아래와 같이 "chromedriver.exe" 를 Python 코드와 동일한 디렉토리에 넣어놓습니다.

이제, 사전작업은 모두 끝났고요....
분석할 웹페이지를 열어서 개발자도구(F12) 를 사용해서 원하는 영역의 태그들을 분석하면 됩니다.
우선 검색창의 정보를 분석하면되는데요...보니깐 input 태그의 id 값이 "query " 임을 확인할 수 있었고요..
("query" 머릿속에 잘 기억해둡니다.)


그리고, View 에 대한 태그를 찾아보니, class 속성값이 "_panel" 이였고요... 해당 속성값이 유일한 값인지 검색을 한번 해봅니다. (검색해본 결과 유일한 값이군요.."_panel" 도 머릿속에 잘 기억해둡니다. )
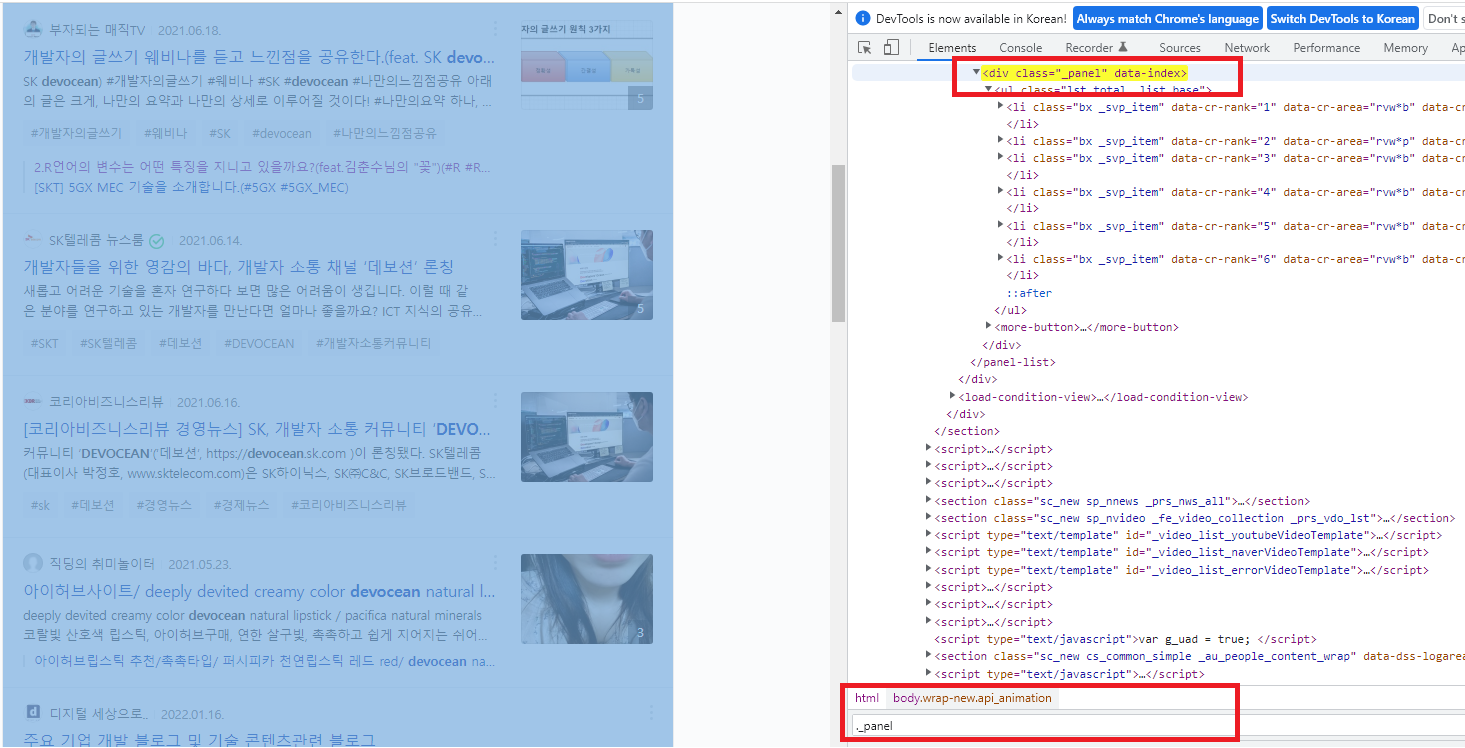
그럼, 위에서 확인한 결과를 토대로 아래 프로그램을 작성해 보겠습니다.
제가 작성한 Python 코드는 아래와 같습니다.
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
driver = webdriver.Chrome('./chromedriver')
options = webdriver.ChromeOptions()
options.add_experimental_option('excludeSwitches', ['enable-logging'])
driver = webdriver.Chrome(options=options)
try:
driver.get('https://naver.com')
keyword = input('search word :')
elem = driver.find_element_by_id('query')
elem.send_keys(keyword)
elem.send_keys(Keys.RETURN)
div = driver.find_element_by_class_name('_panel')
view = div.find_elements_by_xpath('./ul/li')
i = 0
for v in view:
print("---- [%s] -----" % i )
print(v.text)
i+=1
except Exception as e:
print(e)
finally:
driver.quit()
위의 코드의 부연설명은 간단히 하자면...
- 우선 Keys 클래스는 코드에서 표현할 수 없는 키를 입력하고자 할때 사용하는 클래쓰입니다.

- 그리고, 이전에 다운로드 받았던, "chromedriver" 를 로딩하고요...

- 크롬옵션도 지정해서 크롬 드라이버 연결 시 로그들이 노출되지 않게하고요.. (말그대로 옵션..로그를 보고싶으시면 아래내용을 빼면 되겠죠?)

이어서, 위에서 머릿속에 기억해둔 "query", "_panel" 를 소환해서 아래와 같이 코딩을 하면되는데요..
크롬브라우저를 사용해서 "naver 홈페이지"를 실행하고요..
그리고, 찾을 키워드를 입력받습니다. ( 키워드 : devocean)
요소를 찾는 함수를 통해서 query 를 찾아서 초록 검색창(?)의 요소를 받아오고...
해당요소에, Keys 클래스를 사용해서 키워드와리턴을 트리거 시키는 코드를 작성하면됩니다.
그리고 class 속성이 "_panel" 을 찾고나서, 그것을 토대로, 연관된 리스트(ul/li)를 가져온후 화면에 정보를 뿌려주는 코드를 작성한 내용이 아래와 같습니다.

그리고, 깔끔하게 driver 를 닫아주면 됩니다.

아래는 실행 결과입니다.


참고로, 아래는 실제로, 네이버 검색창에 입력한 내용입니다.

잘 추출했음을 확인할 수 있었네요...그럼 결론을 정리해보겠습니다.
결론
하나, Selenium은 웹 브라우저의 자동화를 지원하고 지원하는 다양한 도구 및 라이브러리를 위한 포괄적인 프로젝트라고 머릿속에 넣어두시면 되고요..
둘, 사전작업으로 selenium 라이브러리와 크롬드라이버를 다운로드 받아서 활용할 준비를 합니다.
셋, HTML 관련 "태그"에 대한 사전지식을 공부해두고, 개발자도구(F12)를 통해서 분석하고자하는 웹페이지를 분석해둡니다.
그리고, 주요 키워드를 추출해서 머릿속에 정리해둔다음, 자신이 원하는 목적에 알맞게 Python 코드를 작성하시고 테스트해서 정상이다라고 판별이 나면, 비롯소 모든 절차가 마무리됩니다.
오늘도 마지막까지 제 글을 끝까지 읽어주셔서 진심으로 감사드리고, 제 글이 조금이라도 여러분의 각자의 삶을 살아가시는데 도움이 되셨길 기원합니다.
앞으로도 더욱 좋은 블로그를 남기는 제가 되도록 노력하겠습니다.
그리고, 제 글을 읽으시면 말이 됩니다.
항상 말에는 반드시 삶을 움직이는 힘이 있습니다.
제가 열심히 정성스럽게 정리한 저만의 지식과 1일 1블로그하는 제 블로그에 담긴 글들을 통해서,
여러분들의 삶과 운명을 반드시 조각하고 움직이시길 기원합니다.
이상입니다. 감사합니다.
'좋아하는 것_매직IT > 21.python' 카테고리의 다른 글
| 삼성전자 vs SK하이닉스? Python으로 주가 비교하고 시각화하기 (0) | 2024.11.18 |
|---|---|
| 1.Python 이란 언어에 대해서 알아보자. (0) | 2021.02.16 |
