
블로그 목적
로그를 분석할 수 있는 EFK 스택을 정리해본다.
블로그 요약
- EFK에 대해서 알아본다.
- EFK를 설치하는 방법을 알아본다.
- EFK관련 나의 생각을 간단하게 정리해본다.
EFK 관련 간단한 소개
로그 데이터는 현대 소프트웨어 개발 및 운영에서 중요한 부분을 차지하고 있습니다.
제가 EFK 를 사용하게된 이유는 제가 맡은 업무를 진행하다가 시스템으로 공격이 오더라고요...;;
(한 한달간 방어를 하느라...;;; 힘들었네요.....)
그래서, 해당 공격에 대해서 로그 분석을 하려고 했는데 쉘 명령어(grep, cat 등등)를 통해서 통계서버에서 데이터를 추출해서 보려고 하니 몬가 1%부족함을 느껴서 이번에 EFK 스택을 도입하는 과정에 있습니다.
해당 부분은 이 아티클에서 다뤄보고자 합니다.
로그 분석을 위해서는 데이터를 효과적으로 수집, 저장, 시각화하고 분석하는 것은 서비스를 운영하며 개선및 안정성을 위해 너무너무 중요한데요.
저는 이부분을 해결할 수 있는 것이 공부하다보니 EFK 라고 느꼈고 제가 맡은 서비스에 도입하려고 노력중에 있습니다.
그럼, 차근차근 정리해보도록 할께요~
우선 EFK 스택은 무엇일까요?
EFK 스택은 Elasticsearch, Fluentd, Kibana의 조합으로 이러한 작업을 간편하게 수행할 수 있는 강력한 도구라고 말씀드리고 싶네요.
그럼, Elasticsearch, Fluentd, Kibana에 대해서 간단하게 정리해보자면요 아래와 같습니다.
1.Elasticsearch의 역할 및 특징은?
Elasticsearch는 실시간 분산 검색 및 분석 엔진입니다.
즉, 대용량의 데이터를 저장하고 효과적으로 검색할 수 있는 기능을 가지고 있죠.
특히 JSON 문서로 데이터를 저장하며, RESTful API를 통해 데이터에 접근할 수 있다는 점이 좋은것 같고요..
Elasticsearch 는 뛰어난 확장성과 성능을 제공하여 대규모의 로그 데이터도 효과적으로 처리할 수 있는 장점이 있는 것으로 개인적으로 생각합니다.
2.Fluentd의 역할 및 특징은?
Fluentd는 데이터 수집, 전송 및 로깅을 위한 오픈 소스 플랫폼이라고 머릿속에 넣어두시면 되고요.
json및 어플리케이션 로그등등 다양한 소스에서 로그 데이터를 수집하고 Elasticsearch와 같은 목적지로 전송하는데 사용됩니다.
특히 확장 가능한 플러그인 아키텍처를 통해 다양한 데이터 소스 및 목적지와 통합이 가능하다는 점이 장점이고요.
3.Kibana 의 역할 및 특징은?
Kibana는 Elasticsearch에서 저장된 데이터를 시각적으로 탐색하고 대화식 대시보드를 구축할 수 있는 시각화 도구입니다.
사용자는 효과적인 대시보드를 생성하여 로그 데이터의 트렌드 및 패턴을 쉽게 이해할 수 있습니다.
Kibana 가 없으면 쉘에서 스크립트와 명령어를 통해서 패턴을 분석해야겠죠..
이노력을 조금이나마 줄여줄 수 있는 것이 바로 Kibana 입니다.
이제까지 EFK 스택에 대해서 간단하게 정리해보았는데요.
한마디로 EFK 스택은 로그 데이터를 효과적으로 수집하고 시각화하는 강력한 도구라고 말씀드리고 싶습니다.
Elasticsearch의 검색 엔진, Fluentd의 데이터 수집 및 전송, 그리고 Kibana의 시각화 기능이 조합되어 운영 및 개발 환경에서 로그 데이터 관리를 효율적으로 수행할 수 있습니다.
저도 또한 EFK 스택을 구축해서 제가 맡은 서비스에서 효율적으로 잘 사용해보려고 합니다.
그리고 이를 통해 시스템의 안정성을 높이고 문제를 신속하게 해결할 수 있을것으로 예상해 보네요..
그럼, EFK 를 설치및 기동은 어떻게 할까요?
우선 ElasticSearch 와 Kibana는 Log서버 에서 기동 시켰고요, Fluentd 는 App 서버에 기동시켰습니다.
저는 dockerhub 에서 docker 이미지를 다운로드 받아서 설치했습니다.
그리고 우선 rancher 대신에 docker-compose 를 사용해서 개발장비 에서 간단하게 기동시키고 처리하도록 했습니다.
추후에 어느정도 검증이 되면 rancher 에 등록시켜야 겠죠?
docker-compose
우선 docker-compose 에 대해서 간략하게 설명해보자면요.
Docker Compose는 여러 개의 Docker 컨테이너를 하나의 애플리케이션처럼 정의하고 관리할 수 있도록 도와주는 도구입니다.
마치 레고 블록으로 집을 만드는 것처럼, 여러 컨테이너를 조합하여 복잡한 애플리케이션을 손쉽게 구축하고 실행할 수 있게 해줍니다.
아래는 docker-compose 환경설정입니다.
elasticsearch & kibana
version: '3.9'
services:
es01:
image: elasticsearch:8.12.0
expose:
- 9200
- 9300
ports:
- "9200:9200"
environment:
- discovery.type=single-node
- ELASTIC_PASSWORD=******
volumes:
- $PWD/elasticsearch/config/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml
- esdata:/usr/share/elasticsearch/data
networks:
- elastic
kibana:
image: kibana:8.12.0
environment:
- ELASTICSEARCH_USERNAME=kibana_system
- ELASTICSEARCH_PASSWORD=*******
links:
- es01
depends_on:
- es01
ports:
- "8085:5601"
volumes:
- $PWD/kibana/config/kibana.yml:/usr/share/kibana/config/kibana.yml
networks:
- elastic
volumes:
esdata:
name: esdata
networks:
elastic:
name: elastic간략하게 주요내용을 설명해보자면요.
이 Docker Compose 파일은 버전 3.9의 Compose 명령어 구문을 사용합니다.
elasticsearch 서비스는 아래와 같습니다.
es01:
image: elasticsearch:8.12.0 - Elasticsearch 8.12.0 이미지 사용
expose: 컨테이너 내부 포트 9200(HTTP) & 9300(TCP) 공개
ports: 컨테이너 내부 포트 9200을 호스트 컴퓨터 포트 9200에 매핑
environment: 환경 변수 설정
discovery.type=single-node - 싱글 노드 클러스터 설정
ELASTIC_PASSWORD=******* - Elasticsearch 비밀번호 설정
volumes:
$PWD/elasticsearch/config/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml - 설정 파일 매핑
esdata:/usr/share/elasticsearch/data - 데이터 폴더 매핑 (esdata 볼륨 참조)
networks: elastic 네트워크 참조
kibana 서비스는 아래와 같습니다.
kibana:
image: kibana:8.12.0 - Kibana 8.12.0 이미지 사용
environment: 환경 변수 설정
ELASTICSEARCH_USERNAME=kibana_system - Kibana 시스템 사용자 이름
ELASTICSEARCH_PASSWORD=******* - Elasticsearch 비밀번호
links: es01 컨테이너 연결 (Elasticsearch 연결 설정)
depends_on: es01 컨테이너 시작 전 대기 (Kibana는 Elasticsearch가 실행되어야 함)
ports: 컨테이너 내부 포트 5601을 호스트 컴퓨터 포트 8085에 매핑 (Kibana 웹 인터페이스)
volumes: 설정 파일 매핑
$PWD/kibana/config/kibana.yml:/usr/share/kibana/config/kibana.yml
networks: elastic 네트워크 참조
정리해보자면, Docker Compose 파일은 Elasticsearch 싱글 노드 클러스터와 Kibana를 실행합니다.
설정 파일을 로컬 폴더에서 매핑하고 데이터는 별도 볼륨에 저장합니다.
그리고, Kibana는 Elasticsearch에 연결되도록 설정되어 있습니다.
fluentd
version: '2'
services:
fluentd:
build: ./fluentd
container_name: fluentd
volumes:
- ./fluentd/config:/fluentd/etc
- ./fluentd/var/log/tmp:/var/log/tmp
- /log/mdp2_7007/cmd:/log/mdp2_7007/cmd
ports:
- "24224:24224"
- "24224:24224/udp"version: '2': 이 부분은 Docker Compose 파일의 버전을 지정합니다. 이 경우 버전 2를 사용합니다.
services: fluentd: 이 부분은 Docker Compose 파일에서 설정할 서비스 목록을 나타냅니다. 여기서는 "fluentd"라는 서비스 하나만 정의되어 있습니다.
build: ./fluentd: 이 부분은 "fluentd" 서비스를 위한 빌드 지침을 나타냅니다. .dockerfile 파일이 있는 현재 디렉토리 (.) 에서 빌드 이미지를 사용할 것이며, .dockerfile 파일 내용을 바탕으로 Fluentd 컨테이너 이미지를 만들 것입니다.
container_name: fluentd: 이 부분은 "fluentd" 서비스를 실행할 때 생성되는 컨테이너의 이름을 지정합니다. 컨테이너 이름은 "fluentd"로 설정됩니다.
volumes: 이 부분은 컨테이너 내부 볼륨 매핑을 정의합니다. 세 가지 매핑이 설정되어 있습니다.
./fluentd/config:/fluentd/etc: 현재 디렉토리의 "fluentd/config" 폴더를 컨테이너 내부의 "/fluentd/etc" 폴더에 매핑합니다. 이 폴더는 일반적으로 Fluentd 설정 파일이 저장되는 위치입니다.
./fluentd/var/log/tmp:/var/log/tmp: 현재 디렉토리의 "fluentd/var/log/tmp" 폴더를 컨테이너 내부의 "/var/log/tmp" 폴더에 매핑합니다. 이 폴더는 Fluentd의 임시 파일 저장에 사용됩니다.
/log/mdp2_7007/cmd:/log/mdp2_7007/cmd: 호스트 컴퓨터의 "/log/mdp2_7007/cmd" 폴더를 컨테이너 내부의 "/log/mdp2_7007/cmd" 폴더에 매핑합니다. 이 폴더는 아마 로그 데이터가 있는 곳일 것으로 추측됩니다.
ports: 이 부분은 컨테이너 내부 포트를 호스트 컴퓨터 포트에 매핑합니다. 두 가지 매핑이 설정되어 있습니다.
"24224:24224": 컨테이너 내부의 24224 포트 (TCP)를 호스트 컴퓨터의 24224 포트 (TCP)에 매핑합니다. 기본적으로 Fluentd는 이 포트에서 데이터를 수신합니다.
"24224:24224/udp": 컨테이너 내부의 24224 포트 (UDP)를 호스트 컴퓨터의 24224 포트 (UDP)에 매핑합니다. Fluentd는 UDP 방식으로도 데이터를 수신할 수 있습니다.
따라서, 이 Docker Compose 파일은 현재 디렉토리의 .dockerfile 파일을 사용하여 Fluentd 컨테이너 이미지를 빌드하고 실행합니다.
컨테이너는 설정 파일, 임시 파일, 로그 데이터가 있는 호스트 컴퓨터 폴더를 볼륨으로 매핑하고, 24224 포트 (TCP/UDP)에서 데이터를 수신합니다.
참고로 fluentd 의 Docker 파일입니다.
# image based on fluentd v1.14-1
FROM fluentd:v1.14-1
# Use root account to use apk
USER root
# below RUN includes plugin as examples elasticsearch is not required# you may customize including plugins as you wish
RUN apk add --no-cache --update --virtual .build-deps \
sudo build-base ruby-dev \
&& gem uninstall -I elasticsearch \
&& gem install faraday-net_http -v 3.0.2 \
&& gem install faraday -v 2.8.1 \
&& gem install elasticsearch -v 7.17.0 \
&& sudo gem install fluent-plugin-elasticsearch \
&& sudo gem sources --clear-all \
&& apk del .build-deps \
&& rm -rf /tmp/* /var/tmp/* /usr/lib/ruby/gems/*/cache/*.gem
# copy fluentd configuration from host image
COPY ./config/fluent.conf /fluentd/etc/
# copy binary start file
COPY entrypoint.sh /bin/
RUN chmod +x /bin/entrypoint.sh
USER fluentdocker-compose 의 실행과 중지는 아래와 같이 하면되고요.
실행은 아래와 같이 하면 docker image 도 다운받고 image 가 있으면 기동시켜줍니다.
$ docker-compose up -d #기동
$ docker-compose down #중지환경설정은 아래와 같습니다.
elasticsearch
cluster.name: "app-cluster"
network.host: 0.0.0.0
logger.level: info
path.logs: /usr/share/elasticsearch/logs
xpack.security.enabled: true
xpack.security.enrollment.enabled: false
xpack.security.http.ssl.enabled: false
xpack.security.transport.ssl.enabled: false간략하게 설명해 보자면 아래와 같습니다.
cluster.name: "app-cluster": 이 설정은 Elasticsearch 클러스터의 이름을 "app-cluster"로 지정합니다. 클러스터 내 모든 노드는 동일한 이름을 가져야 서로 인식하고 함께 작동할 수 있습니다.
network.host: 0.0.0.0: 이 설정은 Elasticsearch가 모든 네트워크 인터페이스에서 연결을 수락하도록 합니다. 기본적으로는 127.0.0.1 (루프백 인터페이스)만 허용하므로 클러스터 내 다른 노드나 Kibana와 통신하기 위해서는 변경이 필요합니다.
주의사항: 실제 운영 환경에서는 보안을 위해 특정 IP나 네트워크만 접근 허용하도록 설정하는 것이 좋습니다.
logger.level: info: 이 설정은 Elasticsearch 로그의 상세도를 "info" 레벨로 지정합니다. "info" 레벨은 주요 이벤트와 경고만 기록하고 세부적인 디버깅 정보는 포함하지 않습니다.
필요에 따라 "debug"이나 "trace" 등 더 높은 레벨로 설정할 수도 있습니다.
path.logs: /usr/share/elasticsearch/logs: 이 설정은 Elasticsearch 로그 파일이 저장되는 위치를 지정합니다. 기본값은 이대로 유지하는 것이 좋습니다.
xpack.security.enabled: true: 이 설정은 X-Pack 보안 기능을 활성화합니다. X-Pack은 인증, 권한 부여, 암호화 등 다양한 보안 기능을 제공합니다.
xpack.security.enrollment.enabled: false: 이 설정은 X-Pack 보안 자격 증명 자동 생성 기능을 비활성화합니다. 이 기능은 처음 클러스터를 시작할 때 기본 비밀번호를 생성하지만 보안상의 이유로 직접 설정하는 것이 좋습니다.
xpack.security.http.ssl.enabled: false: 이 설정은 HTTP 통신 채널 암호화를 비활성화합니다. HTTP 통신은 기본적으로 암호화되지 않으므로 데이터 누출 위험이 있습니다. 실제 운영 환경에서는 반드시 활성화하는 것이 좋습니다.
xpack.security.transport.ssl.enabled: false: 이 설정은 클러스터 내 노드 간 통신 채널 암호화를 비활성화합니다. 노드 간의 통신은 기본적으로 암호화되지 않으므로 데이터 유출 위험이 있습니다. 실제 운영 환경에서는 반드시 활성화하는 것이 좋습니다.
요약: 이 설정들은 Elasticsearch 클러스터의 기본적인 동작, 로깅, 그리고 X-Pack 보안 기능 활성화 여부를 결정합니다.
kibana
server.host: "0.0.0.0"
server.shutdownTimeout: "5s"
elasticsearch.hosts: ["http://es01:9200"]
monitoring.ui.container.elasticsearch.enabled: true
elasticsearch.ssl.verificationMode: "none"간략하게 설명해 보자면 아래와 같습니다.
server.host: "0.0.0.0": Kibana가 모든 네트워크 인터페이스에서 연결을 수락하도록 합니다. 기본적으로는 127.0.0.1 (루프백 인터페이스)만 허용하므로 다른 호스트나 컨테이너에서 접속하기 위해서는 변경이 필요합니다.
주의사항: 실제 운영 환경에서는 보안을 위해 특정 IP나 네트워크만 접근 허용하도록 설정하는 것이 좋습니다.
server.shutdownTimeout: "5s": Kibana 종료 시 프로세스 종료까지 기다리는 최대 시간을 5초로 설정합니다.
elasticsearch.hosts: ["http://es01:9200"]: Kibana가 연결할 Elasticsearch 클러스터의 주소를 설정합니다. "http://es01:9200"은 이 Docker Compose 파일에서 정의된 "es01" 서비스의 포트 9200을 가리킵니다.
monitoring.ui.container.elasticsearch.enabled: true: Kibana 내부 모니터링 기능에서 Elasticsearch 컨테이너 상태 모니터링을 활성화합니다.
elasticsearch.ssl.verificationMode: "none": Kibana와 Elasticsearch 간의 통신에서 SSL 인증서 검증을 수행하지 않도록 설정합니다. 보안상 좋지 않은 설정이며, 실제 운영 환경에서는 반드시 인증서 검증을 활성화해야 합니다.
fluentd
<source>
@type tail
path /log/mdp2_7007/cmd/mdp2_cmd.*.log
pos_file /var/log/tmp/mdp2_cmd.pos
tag mdp2_cmd_stage_02
format none
</source>
<filter mdp2_cmd_stage_02>
@type grep
<regexp>
key message
pattern LIN2
</regexp>
</filter>
<filter mdp2_cmd_stage_02>
@type parser
key_name message
reserve_data true
<parse>
@type regexp
expression \[(?<timestamp_server>[^\]]+)\] (?<ip>[^ ]+) (?<id>[^ ]+) (?<loc_key>[^ ]+) (?<pcid>[^ ]+) (?<cmn>[^ ]+) (?<req_code>[^ ]+) (?<trid>[^ ]+) (?<res_code>[^ ]+) (?<langos>[^ ]+) (?<client_ver>[^ ]+) (?<os_ver>[^ ]+) (?<model>[^ ]+) (?<inst_method>[^ ]+) (?<enc_type>[^ ]+) (?<tkn_type>[^ ]+) (?<ci_yn>[^ ]+) (?<ti_yn>[^ ]+) (?<rf_yn>[^ ]+)
</parse>
</filter>
<match mdp2_cmd_stage_02>
@type elasticsearch
host 172.18.249.143
port 9200
user elastic
password xxxxxx
logstash_format true
logstash_prefix fluentd
logstash_dateformat %Y%m%d
include_tag_key true
tag_key @logname
</match>이 설정은 Fluentd를 사용하여 로그 파일에서 로그를 읽어와 Elasticsearch로 전송하는 환경설정입니다.
참고로 아래는 주요 라인별 설명입니다:
- <source> 블록: 로그를 읽어오는 소스에 관한 설정입니다.
- @type tail: 파일의 끝에서부터 증분 방식으로 로그를 읽어오는 tail 입력 플러그인을 사용합니다.
- path /log/mdp2_7007/cmd/mdp2_cmd.*.log: 로그 파일의 경로 및 파일 패턴을 지정합니다.
- pos_file /var/log/tmp/mdp2_cmd.pos: 파일의 읽기 위치를 추적하기 위한 포지션 파일의 경로를 지정합니다.
- tag mdp2_cmd_stage_02: 읽어온 로그에 부여할 태그를 지정합니다.
- format none: 로그의 형식을 지정하는데, 여기서는 형식이 없다는 의미로 "none"을 사용합니다.
- <filter mdp2_cmd_stage_02> 블록: 로그를 필터링하는 설정입니다.
- @type grep: 메시지 중 "LIN2" 패턴을 포함한 로그만을 선택하는 grep 필터 플러그인을 사용합니다.
- <regexp> 블록: message 필드에서 "LIN2" 패턴을 찾아 선택합니다.
- @type parser: 선택된 로그를 파싱하여 필드로 추출하는 설정입니다.
- key_name message: 파싱 대상이 되는 필드의 이름을 지정합니다.
- reserve_data true: 파싱 이후에 원본 데이터를 유지하도록 설정합니다.
- <parse> 블록: 정규표현식을 사용하여 로그를 필드로 파싱합니다.
- <match mdp2_cmd_stage_02> 블록: 파싱된 로그를 Elasticsearch로 전송하는 설정입니다.
- @type elasticsearch: Elasticsearch로 로그를 전송하는 출력 플러그인을 사용합니다.
- host 172.18.249.143: Elasticsearch 호스트의 주소를 지정합니다.
- port 9200: Elasticsearch의 HTTP 포트 번호를 지정합니다.
- user elastic, password xxxxxx: Elasticsearch에 연결할 때 사용할 사용자 이름과 비밀번호를 지정합니다. (비밀번호는 생략(xxxxxx 로..))
- logstash_format true: Logstash의 JSON 형식으로 로그를 전송하도록 설정합니다.
- logstash_prefix fluentd: Logstash의 인덱스 접두사를 지정합니다.
- logstash_dateformat %Y%m%d: Logstash의 인덱스 생성 날짜 형식을 지정합니다.
- include_tag_key true: 전송하는 로그에 태그 정보를 포함하도록 설정합니다.
- tag_key : tag의 key, ex) {"@logname" : "mdp2_cmd_stage_02"}
해당 설정을 통해 Fluentd는 LIN2 로그와 같은 특정 패턴을 갖는 로그를 읽어와 필터링 및 파싱한 뒤 Elasticsearch로 전송하게 됩니다.
여기까지 설정하시고 아래와 같이 elasticsearch와 kibana는 docker-compose 를 통해서 기동을 하시면 됩니다.

중지는 아래와 같이 하시면 됩니다.

그리고 fluentd 도 docker-compose 를 통해서 기동하시면 되고요..

중지도 아래와 같이 하시면 됩니다.

그리고 로그가 어느정도 쌓인것을 확인후 kibana에 접속해 보시면 아래와 같이 로그를 분석하실 수 있습니다.
우선 로그인하시고요...

아래와 같이 Discover 메뉴를 통해서 통계확인 가능합니다.

아래와 같이 Pie 로도 보실 수 있습니다.
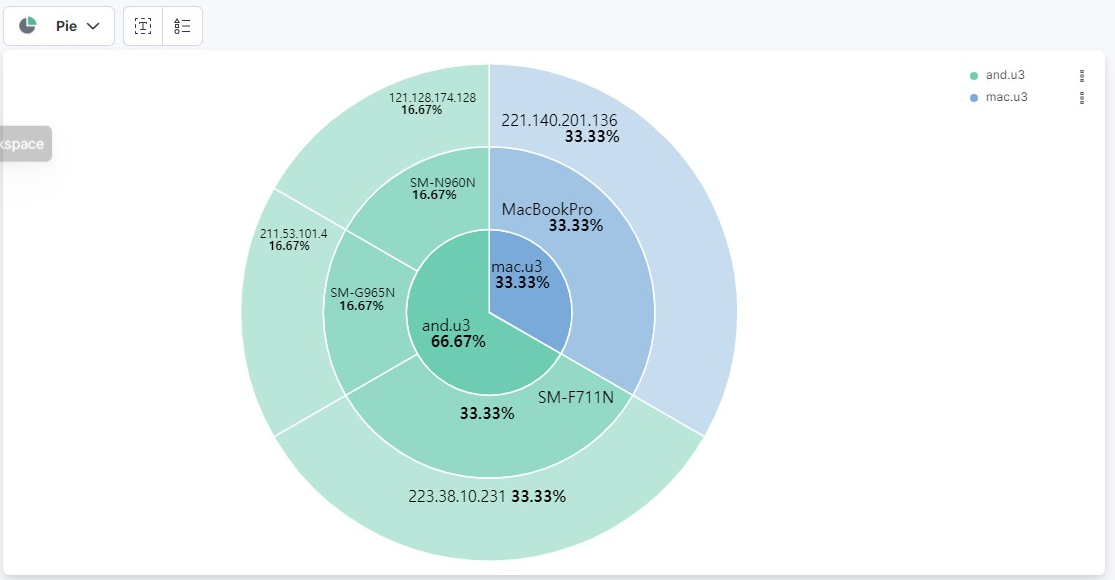
오늘의 티스토리는 여기까지고요.
항상 믿고 봐주셔서 감사합니다.
'좋아하는것_부자되는매직TV' 카테고리의 다른 글
| SOXL ETF 투자자들에게 좋은 소식: 엔비디아 시총 1조 7천억 달러 돌파! (0) | 2024.02.09 |
|---|---|
| TQQQ 하락장에서 분할매수 해야하는 3가지 이유 (0) | 2024.02.07 |
| 엔비디아 사상 최고가 또 경신한 이유 3가지 (0) | 2024.02.05 |
| SOXL 단기투자보다 정액분할매수를 통한 장기투자를 하게된 이유? (0) | 2024.02.04 |
| 저PBR 주식 코리아 디스카운트, 낮은 가격에 숨겨진 가치는? (0) | 2024.02.04 |



